Making AI-driven research understandable, steerable, and verifiable at the point of use.
As AI agents move from simple chatbots to autonomous "researchers," the user experience is fracturing. Current Deep Research agents often work for long, asynchronous periods (5–20 minutes) without human intervention, only to deliver a "sudden" final report. This "Black Box" workflow leaves users unable to verify logic or steer progress, leading to a risk of over-reliance on hallucinations or total under-adoption.
This case study features a solo design project within a 10-week Direct Research Group "Designing the Future of Human-Agent Interaction" (Fall 2025), led by Kevin Feng (Ph.D.) and Prof. David McDonald at University of Washington.
The project envisioned a future paradigm of AI agents that go beyond automation tools and become effective collaborators to humans while remaining within our oversight and control.
The Goal
Explore interaction patterns for LLM-based research agents that helps users make better judgments by improving visibility, control, and verification throughout the research workflow.
Solution Demo
Core Impact & Value
The proposed designs aimed to transform the Research Agent from an opaque automation tool into a reliable research partner by delivering three key outcomes:
Operational Efficiency: Reducing the human verification effort by providing a traceable audit trail and mid-run steering.
Human-Agent Alignment: Shifting the user from a passive consumer to a "Director," ensuring AI behavior aligns with human intent.
Governance Readiness: Introducing "Rules of Engagement" as a policy layer that makes agent behavior more consistent and reviewable, laying groundwork for enterprise oversight.
My Role
UX Designer (solo)
Advisor
Kevin Feng (Ph.D.),
Prof. David McDonald
@ University of Washington
Timeline
10 weeks,
Oct - Dec 2025
Tools
Figma (Design)
Gemini (LLM logic, Early prototyping)
Figma Make, Lovable (High-fi prototyping)
Deep Research Agent can Offer High Value

Yet… its "Black Box" of Autonomy Erodes User Trust
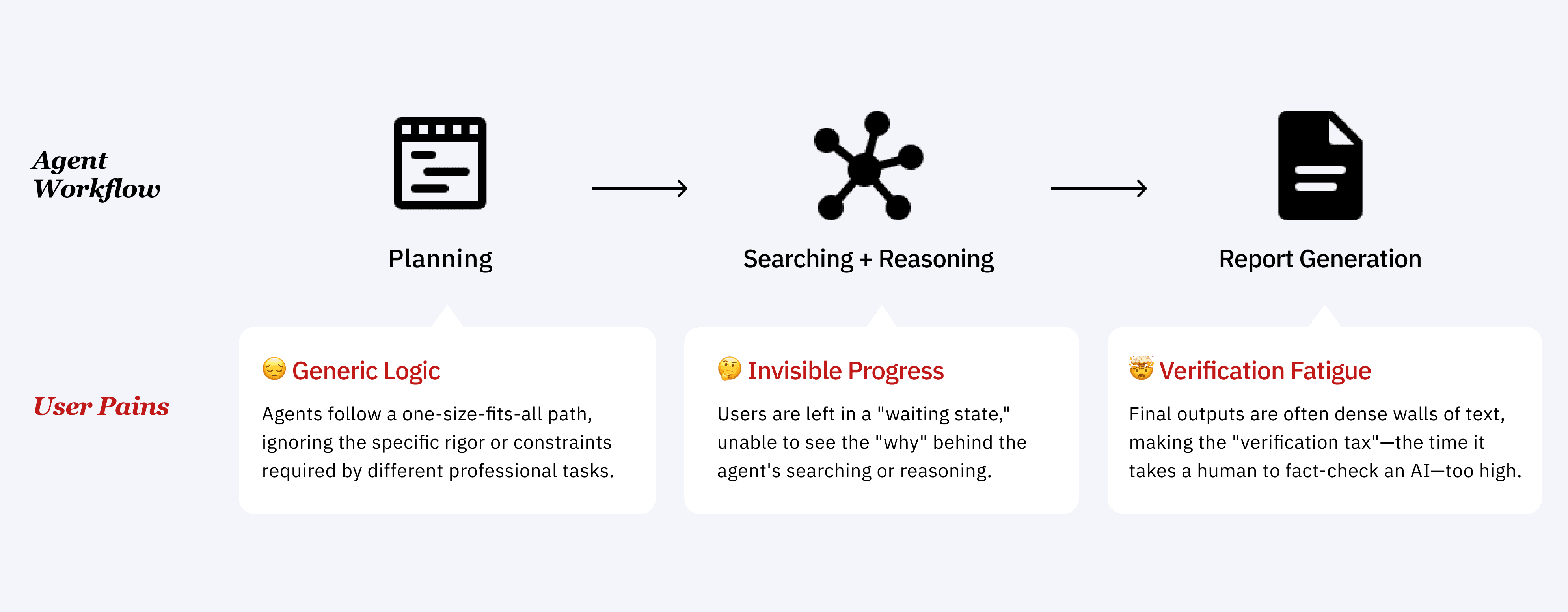
User Journey & Friction Points
The Core Problem
Failure in Establishing Common Ground
As agents operate autonomously over extended workflows, they often fail to establish shared context with users, making it difficult to understand, steer, or confidently rely on their outputs.
Design goals
To facilitate human-agent collaboration and enhance user trust in the research flow, I developed 3 strategic interventions to transform the agent from an opaque tool into a transparent research partner.
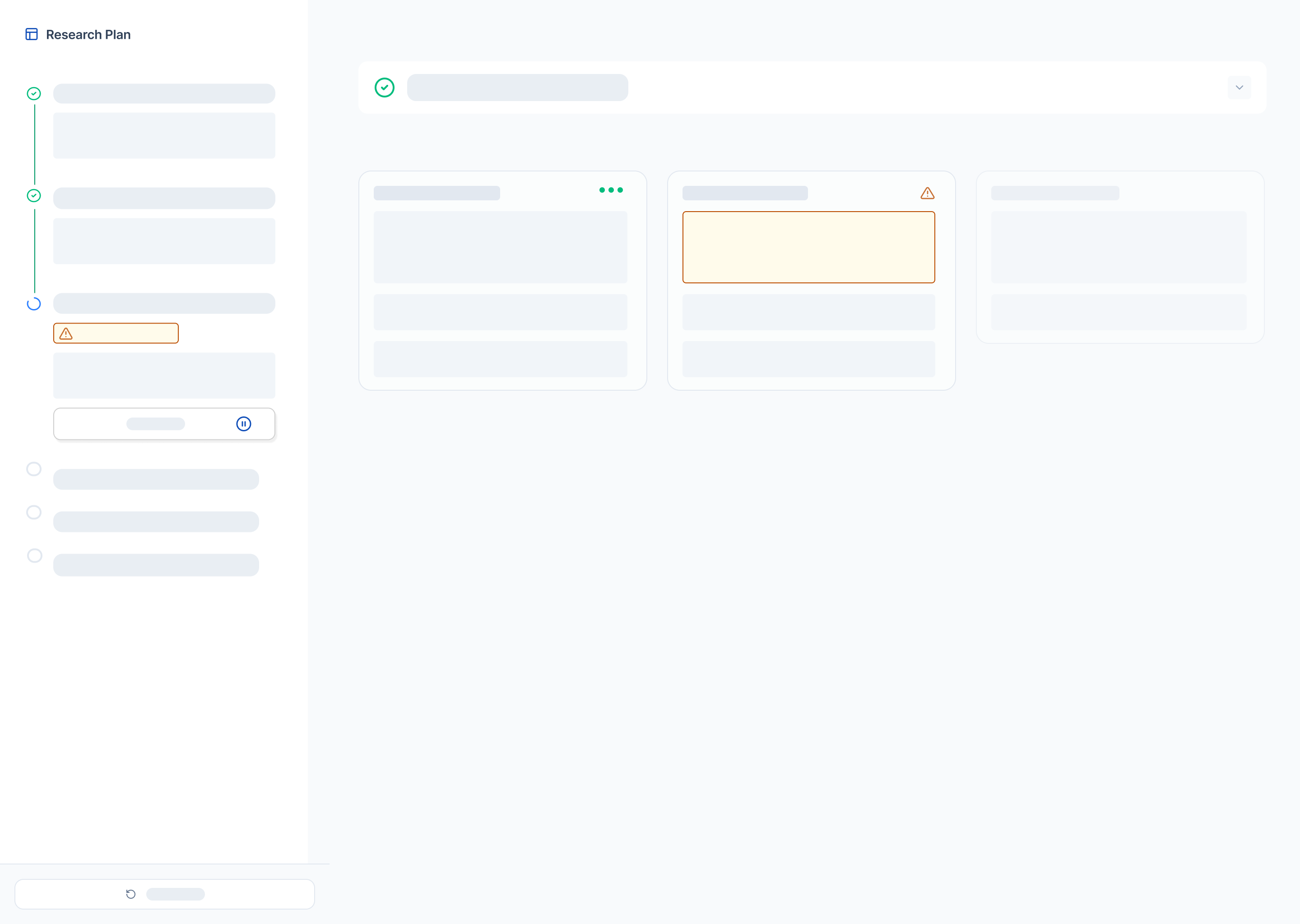
Architecting Visibility (Decoupling Plan & Execution)
Problem:
Linear Density Hinders Strategic Oversight
In current agentic interfaces, the line between Goal (the plan) and Action (the execution) is often blurred. Actions are presented in a dense, linear stream of raw logs. While this provides technical transparency, it creates a massive "Context Recovery" problem: if a user steps away and returns, they are met with a visually overwhelming wall of data that makes it impossible to distinguish what was planned from what has actually been done.
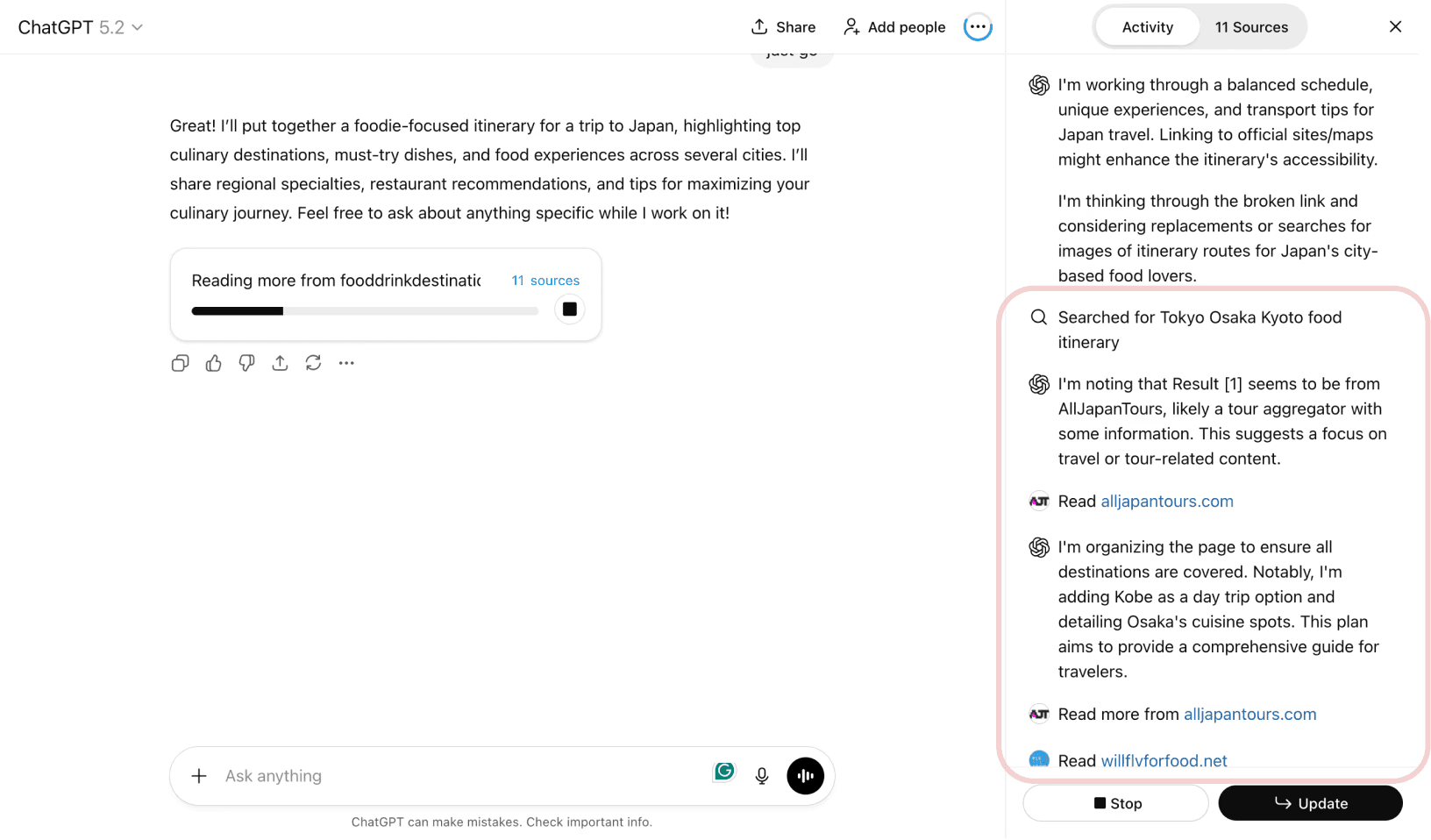
Current ChatGPT Deep Research Information Architecture
Solution:
Separating Goal from Action
To resolve this "Planning-Execution Blur," I separated the agent’s internal state into two distinct, persistent views. This allows users to recover context instantly, regardless of when they check in on the agent's progress.
Planner Panel (The "What"): A dedicated space for the overarching strategy. It visualizes high-level goals and status, ensuring the user always knows the "North Star" of the research session.
Execution Canvas (The "How"): A granular feed of real-time actions. By moving the "noise" of searching and reasoning to a separate canvas, the user can dive into the details without losing sight of the big picture.
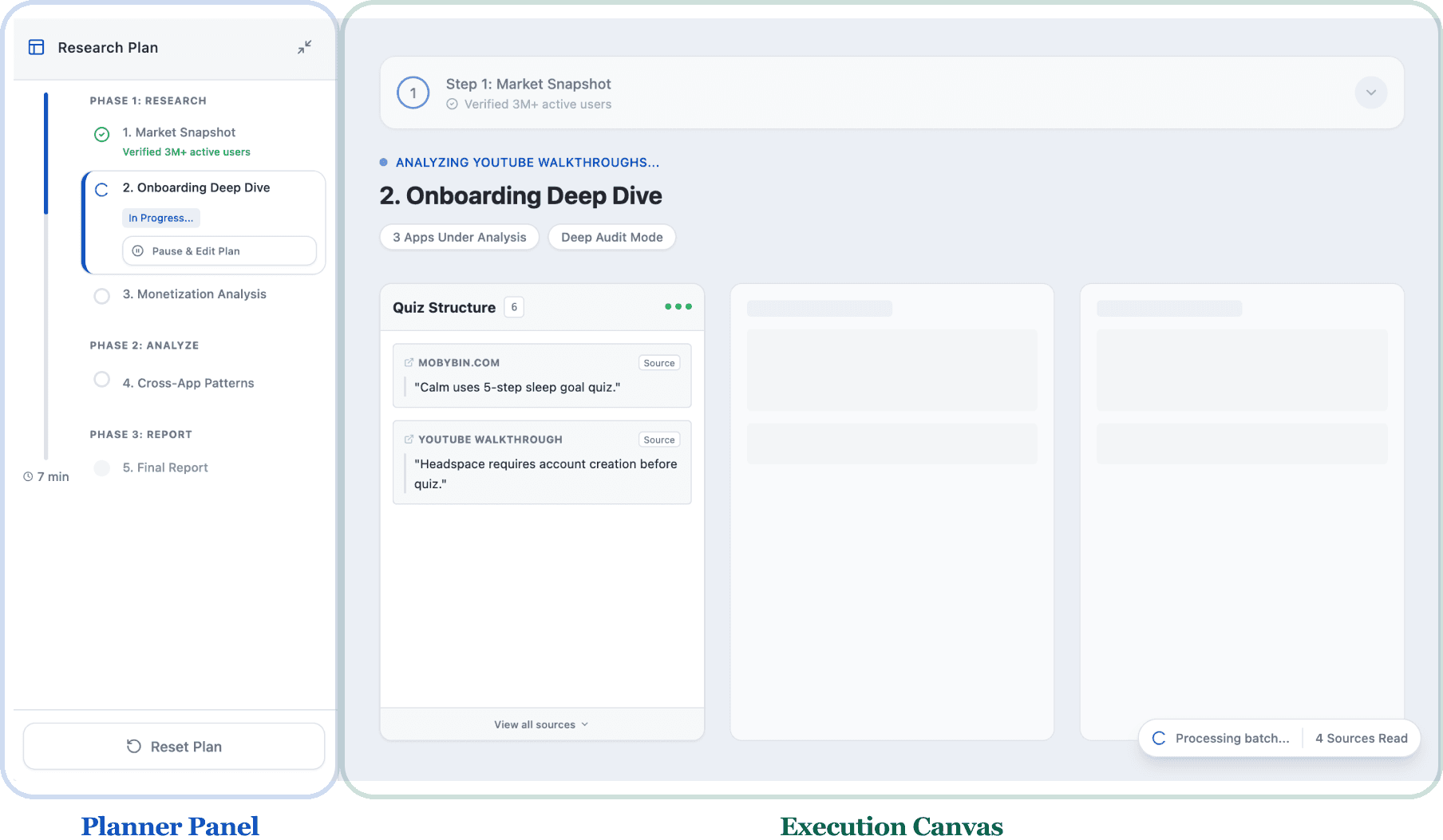
Information Architecture: 2 Distinct Views of Goal and Action
Foundations for Micro-Steering
By separating the views, the architecture sets the stage for "Micro-Steering." This allows for a "Pause & Edit" interaction where users can intercept and redirect specific steps mid-run without the cognitive overhead of parsing through execution logs, nor wasting compute on a full restart.
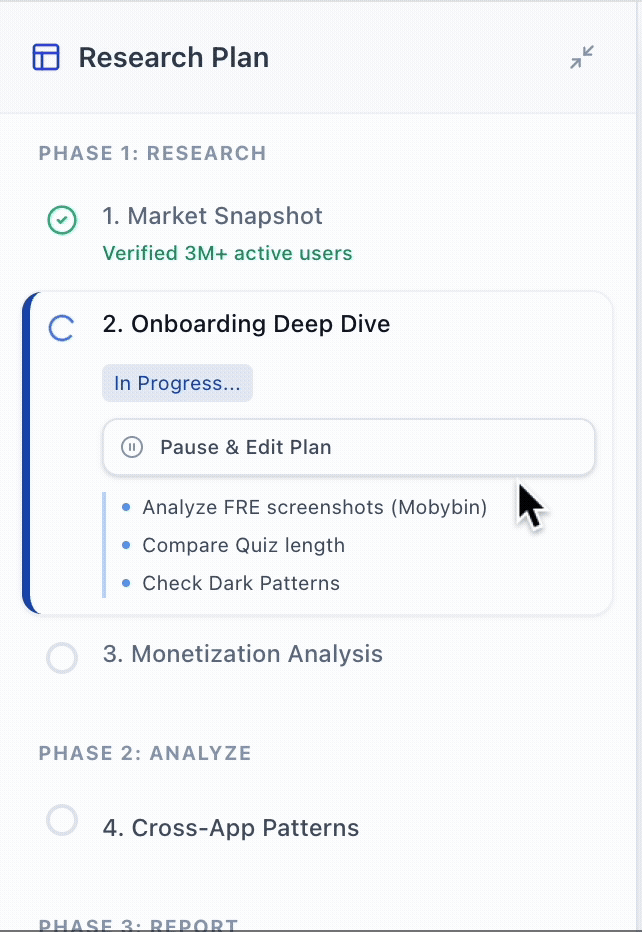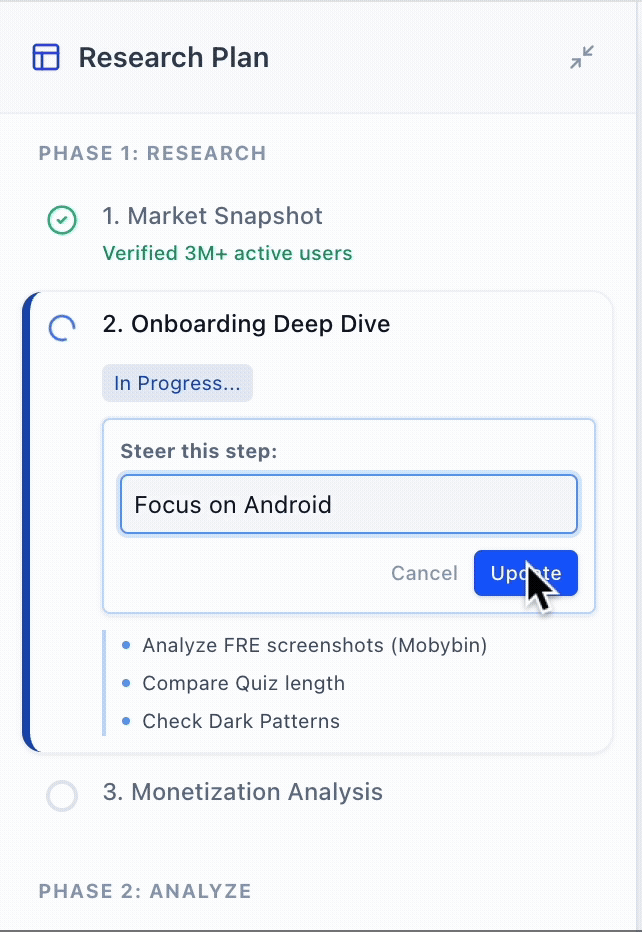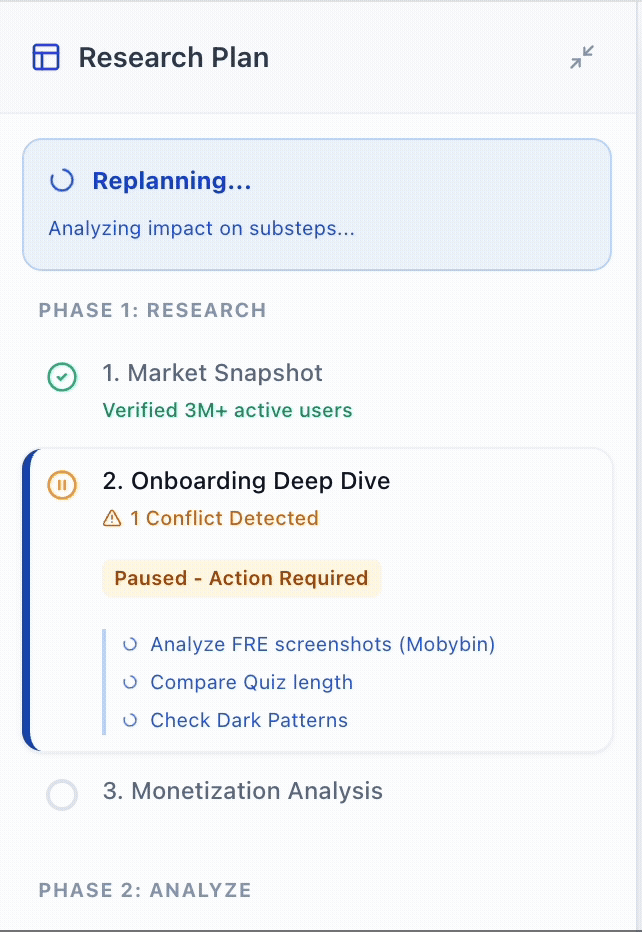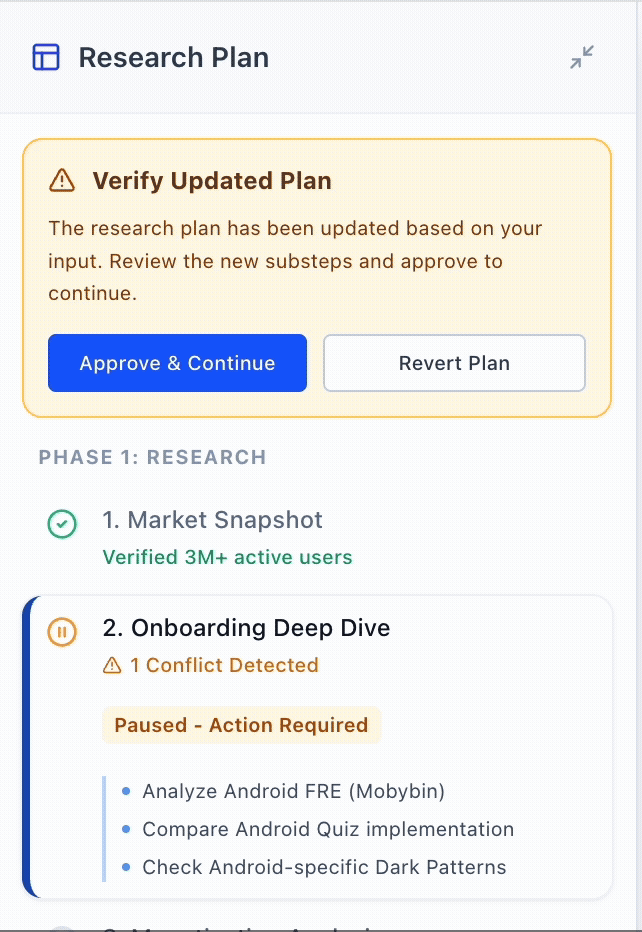
Pause & Edit Steps Mid-Run
Meaningful Reasoning Signals (From "Efforts" to "Value")
Problem:
High Cost of Verification
Current market solutions attempt transparency by displaying "Chain-of-Thought" as raw text logs. While this provides technical visibility, it fails to provide a usable mental model for the user: in reality, users rarely read dense text; they just wait for them to finish. Clearly, this Chain-of-Thought approach fails to support efficient user evaluation. Hence, I wanted to move away from these unreadable text streams and explore a more intuitive way of surfacing the agent's progress.

Current Gemini Deep Research Chain-of-Thought
Early Exploration:
Visualize the "Thoughts"
As human cognition processes spatial patterns and quantity much faster than linear text, I hypothesized that a visual-first approach would establish trust more effectively than text-heavy logs. Hence, I intended to transform the agent's invisible "thinking" into a tangible, observable process that the user could gauge at a glance.
I first attempted to visualize the process by showing mockup cards for every article the agent accessed.

My Early Exploration: Visualization of Sources Viewed
Challenge:
The "Cognitive Load Trap"
However, after I prototyped and presented this design to our research group, critique revealed two critical areas for improvement:
Narrow Scope: The representation felt too "academic" and didn't translate well to broader use cases like shopping or travel.
High Cognitive Load: Showing every single source meant users still need to closely follow the agent. Users may easily feel overwhelmed by the "noise" of the process and were forced to do the heavy lifting of synthesis themselves to determine if the agent was actually on the right track.
Solution:
Surface Information Value via Semantic Clustering
The feedback led to a critical realization: simply "showing work" isn't the same as "building trust." To facilitate true collaboration, I decided to shift the focus from visualizing the process (what the agent is literally doing) to visualizing the synthesis (what the agent is actually learning).
Showing the "Signal": Instead of a stream of URLs or article cards, the agent now groups findings into live semantic clusters that synthesize patterns in real-time.
Glanceable Evaluation: By surfacing the information value upfront, users can evaluate the agent’s decisional logic at a glance and intervene the moment the logic drifts.
Traceable Reasoning: Transparency is maintained by tying each cluster back to its sources, allowing users to verify the reasoning instantly without deciphering raw logs.

Live Semantic Clustering to Show Work In-Progress
User-Centered Governance (The Alerting Lifecycle)
Problem:
Rigid Automation Erodes User Trust
Trust is personal, context-aware, and earned through consistency. In current agentic workflows, users are passive recipients of built-in system loops. Agents are often rigid and prescriptive, treating a casual "shopping research" with the same logic as a "high-stakes legal audit," ignoring that these tasks require vastly different levels of human-in-the-loop engagement. Furthermore, agents often make "invisible" autonomous decisions (e.g., skipping paywalled content or choosing between conflicting facts) without any user governance.
Current Gemini Deep Research - Full Autonomous
Research Inspiration:
Surfacing Trust through Confidence Scores
Inspired by the literature we reviewed, I looked to the concept of "Confidence Levels" as a way to surface agent certainty. I experimented with the idea that integrated numerical scores into the report to support backtracking and verification. The hypothesis is that if a user saw a "70% Confidence" score, they would know which parts of the report required manual fact-checking.
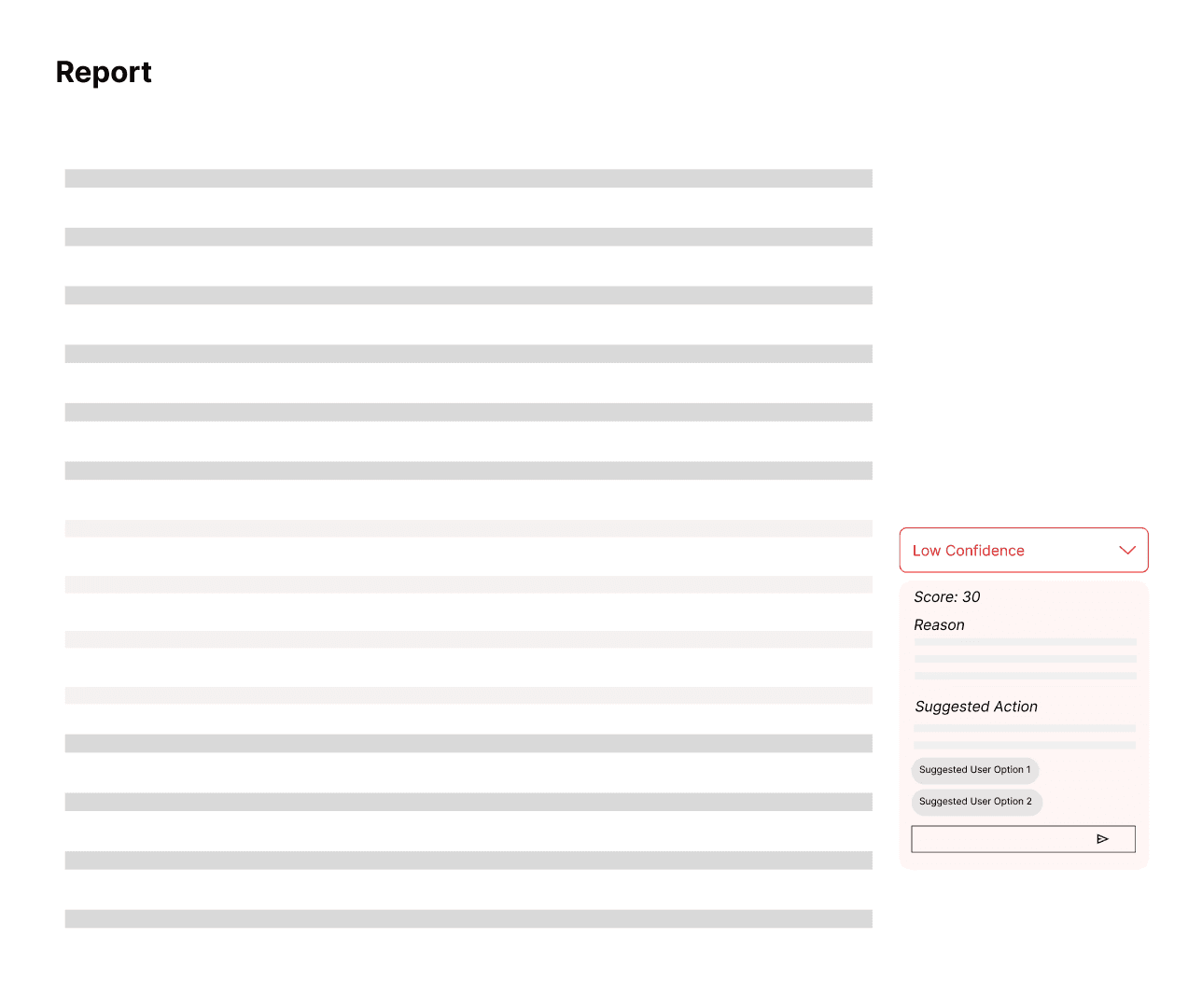
My Exploration: Showing Confidence Score to User
Challenge:
Technical Data v.s. Human Utility
However, feedback from my critique sessions highlighted a fundamental mismatch between data and utility:
The "Late-to-Action" Problem: Confidence is a dynamic state, not a static post-script. Showing a score only in the final report is too late to influence the outcome.
The "Jargon" Barrier: "Confidence Level" is an abstract, technical term that lacks a shared meaning among laypeople. It tells a user that the agent is unsure, but falls short in helping general users understand why or offer a clear path to correction.
Solution:
Active User Governance via Customized Alerting System
I translated the technical "Confidence Level" concept into a proactive lifecycle that moves "invisible decisions" into the user's control through a customized alerting system.
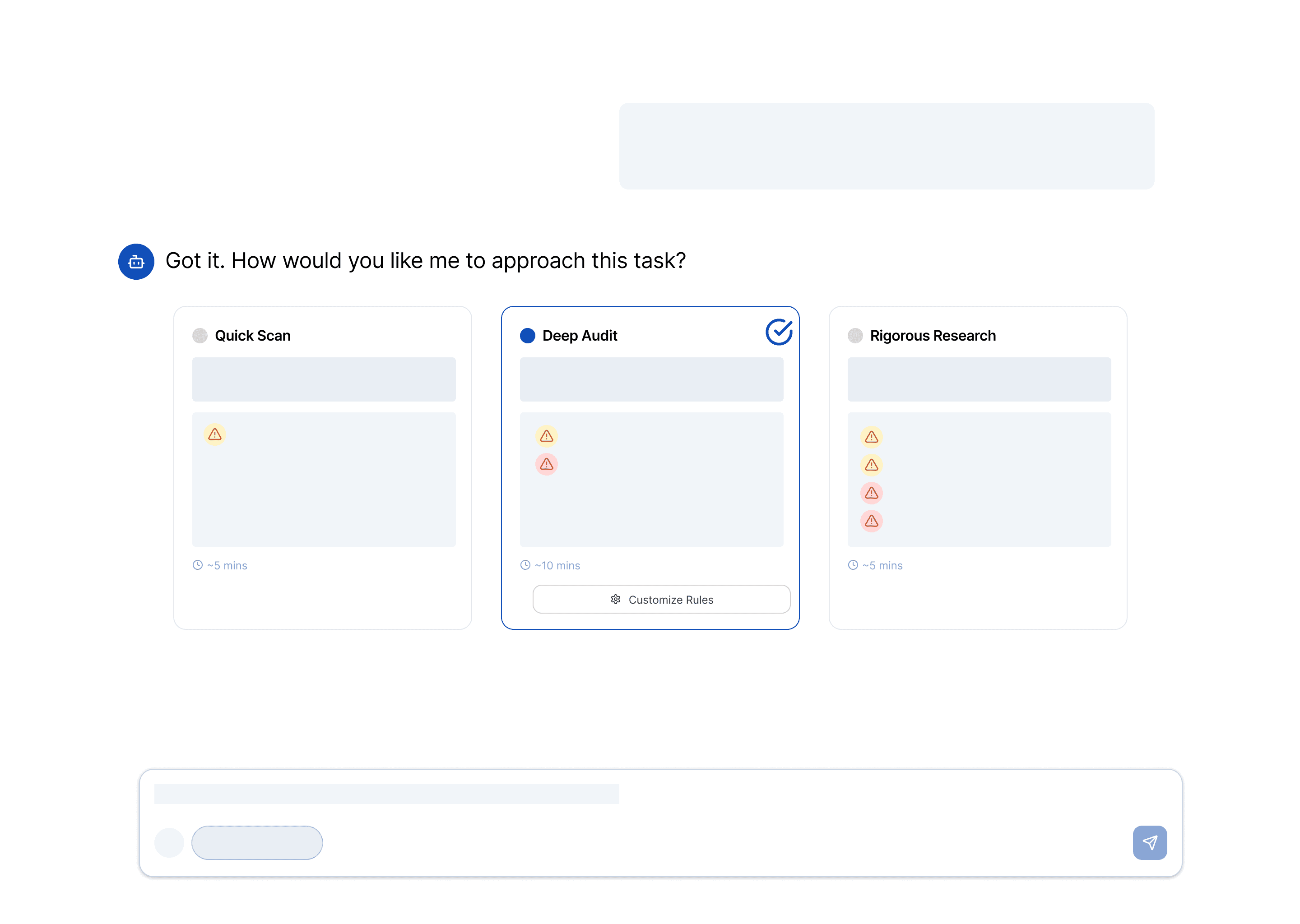
Stage 1: Pre-Execution — Approach Cards
To solve the "One-Size-Fits-All" problem, I designed Approach Cards. Instead of burying instructions in a research plan, these cards allow users to define explicit "Rules of Engagement" (e.g., how to handle paywalls or sources to check out) before the task starts.
Pre-defined Personas: For the cards, I created pre-defined personas based on common use cases (e.g., Quick Scan vs. Rigorous Research) to support rapid task setup and avoid choice fatigue.
Customizable Rules: While the templates provide a strong starting point, users have the flexibility to further edit specific rules—such as paywall handling, data age, and citation rigor—to perfectly match their individual preferences and the stakes of the research.
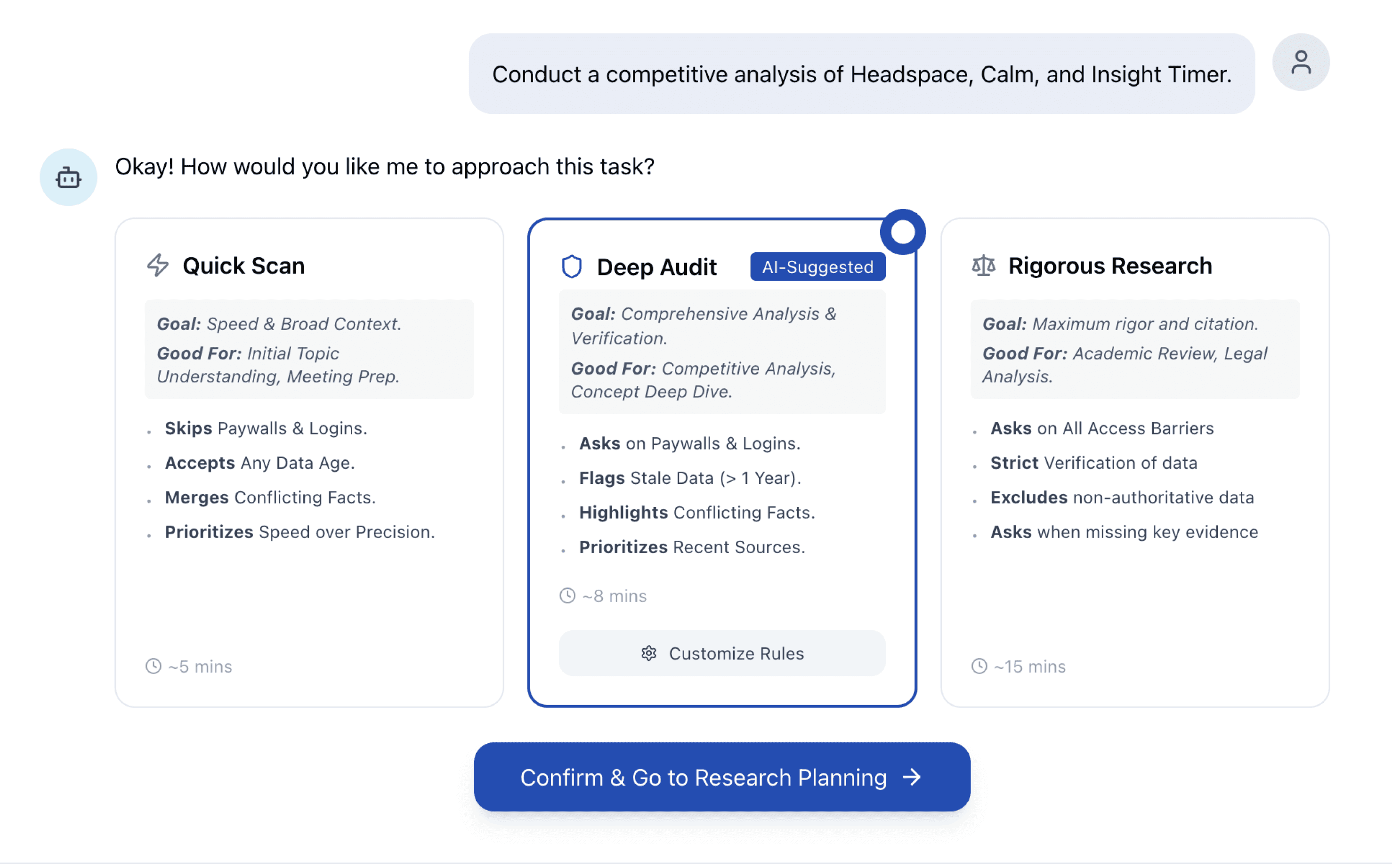
Approach Cards with Engagement Rules
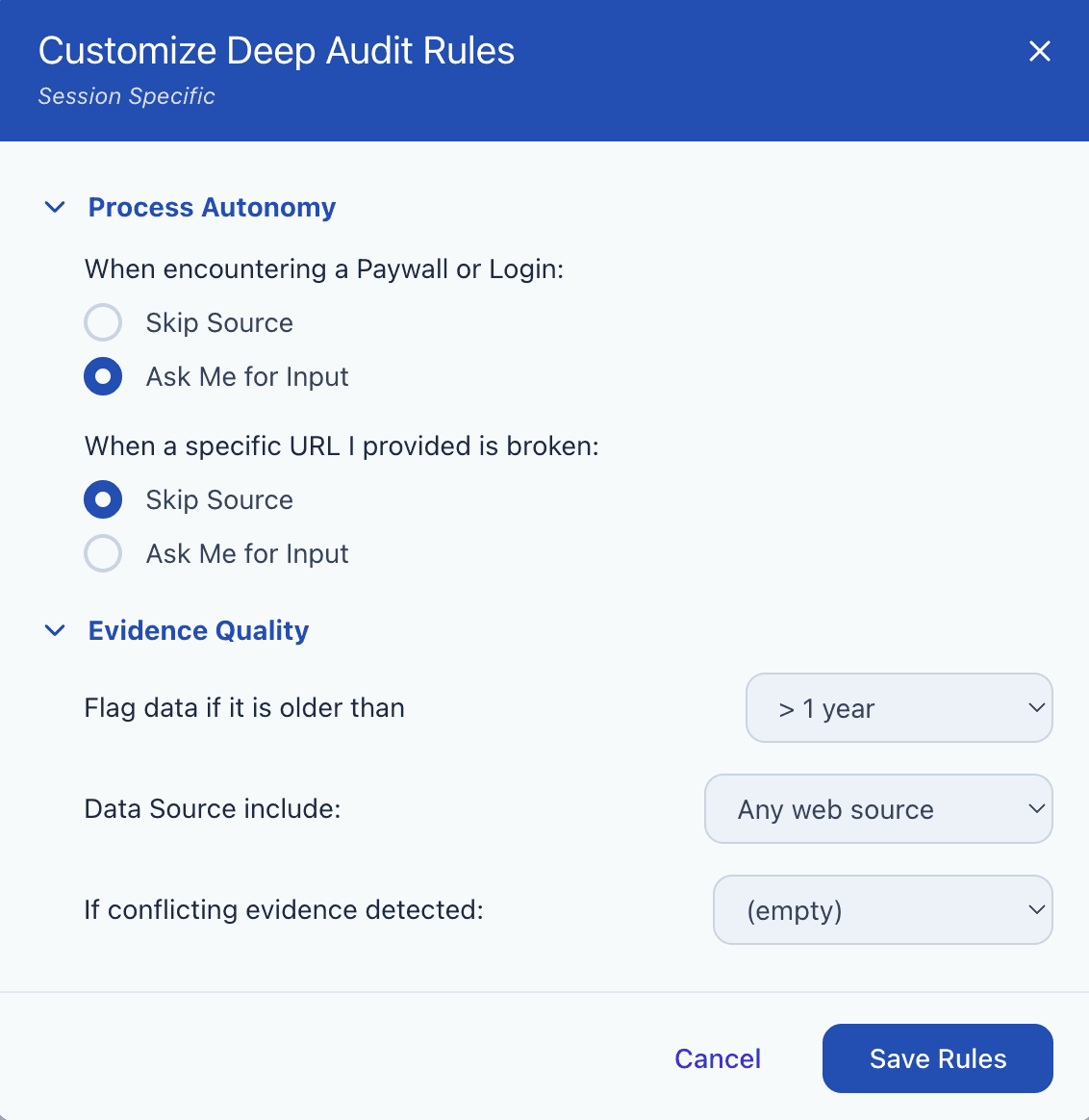
Customizable Rules
Stage 2: During Execution — Alerts & Interventions
Instead of silent failure or a hidden score, the agent uses reactive nudges and proactive pauses to get human input in real-time. This transforms invisible decisions into collaborative checkpoints.
I categorized incidents into two clear signals, both defined in user rules, to manage user friction and prevent "alert fatigue" so that users are only interrupted when they have deemed important.
Reactive Nudges (Evidence Quality): Flags for review (e.g., conflicting facts or stale data) that appear without stopping the agent's momentum.
Proactive Pauses (Process Autonomy): Hard stops for critical barriers the agent cannot resolve alone, such as login walls or broken URLs.
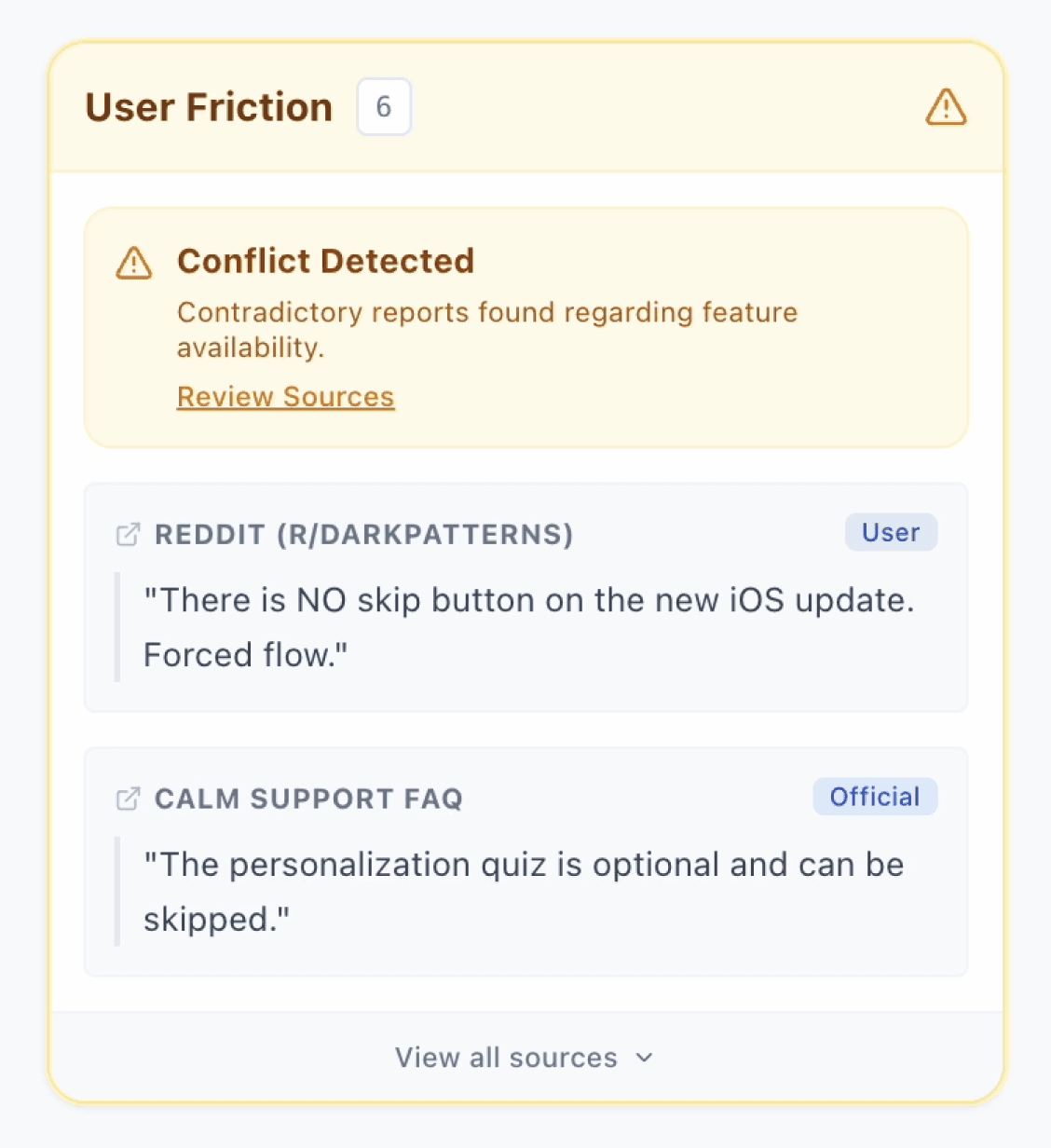
Reactive Nudge Alerts
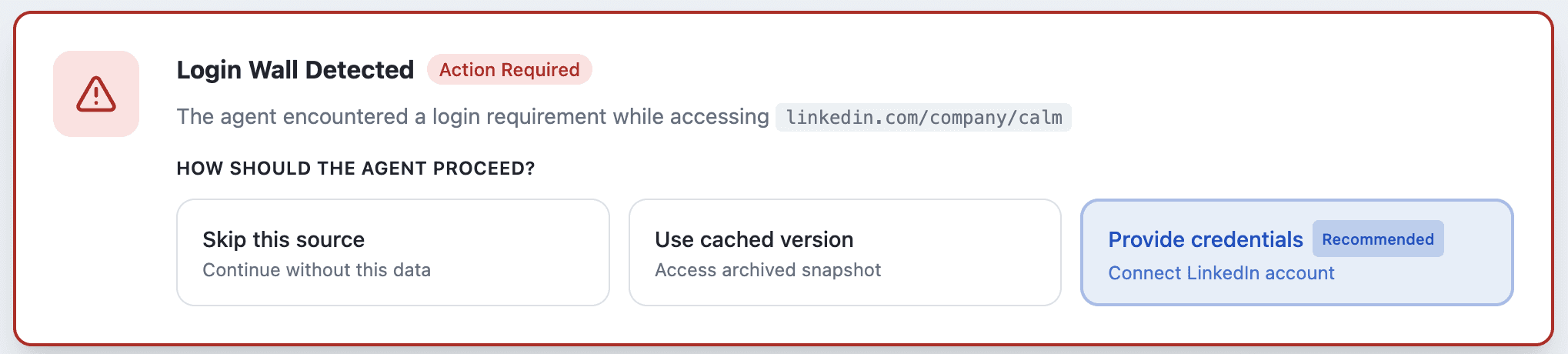
Proactive Pause Alerts
Stage 3: Post-Execution — Audit-Ready Report
Traditional AI reports are static and difficult to verify. I designed the final deliverable to be an interactive audit trail that supports Targeted Verification.
Macro & Micro Evaluation: The Health Summary provides a dashboard of output quality at a glance, while Interactive Chips allow users to view underlying evidence for specific claims without leaving the report context.
Source Transparency: A full list of Discarded Sources (and the "why" behind them) ensures the user understands what the agent ignored, preventing "silent" bias.
Historical Traceability: By linking the report back to the Work Log, users can backtrack through the agent's chronological progress, providing a complete "black box recording" of the entire research session.
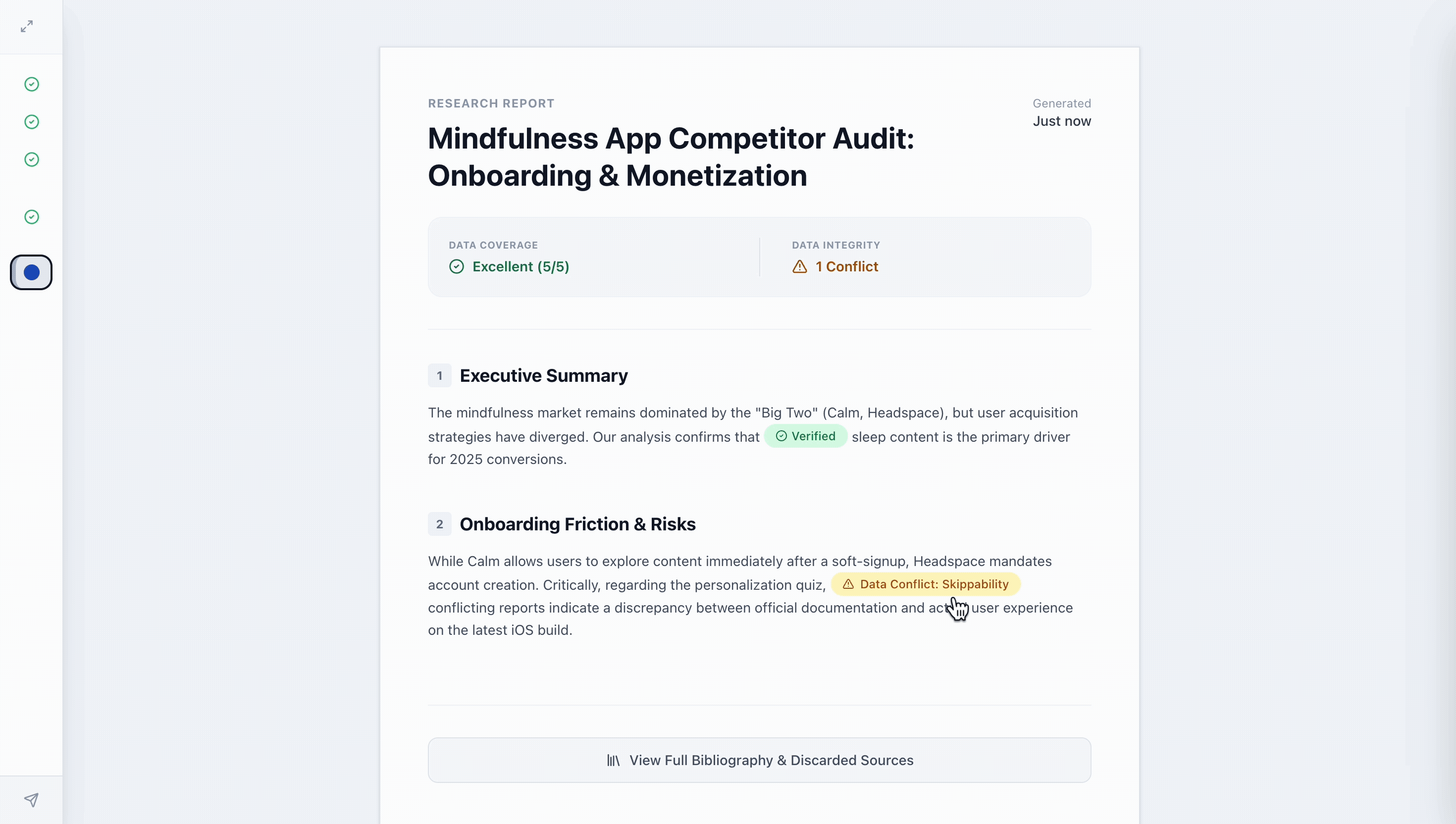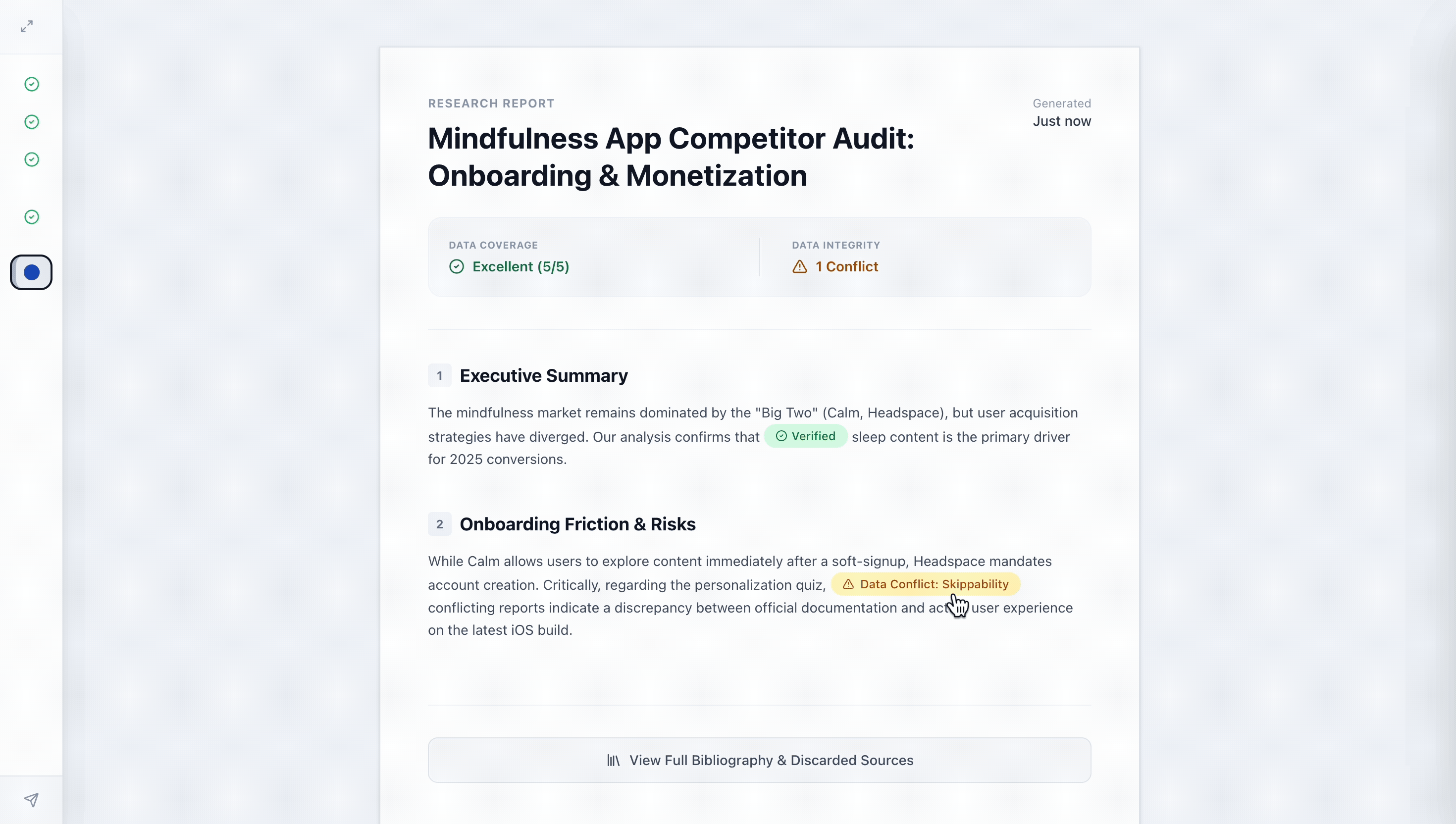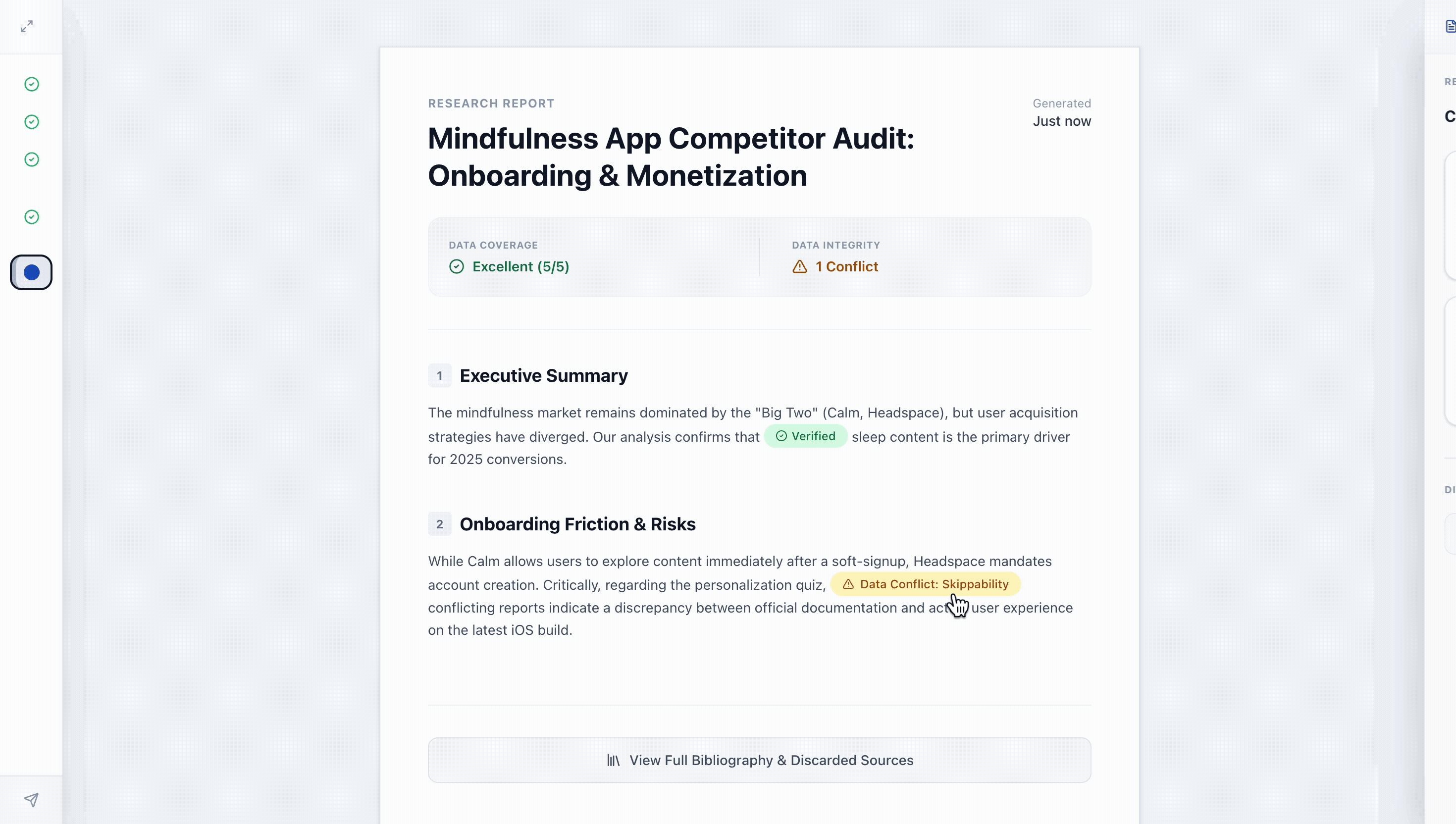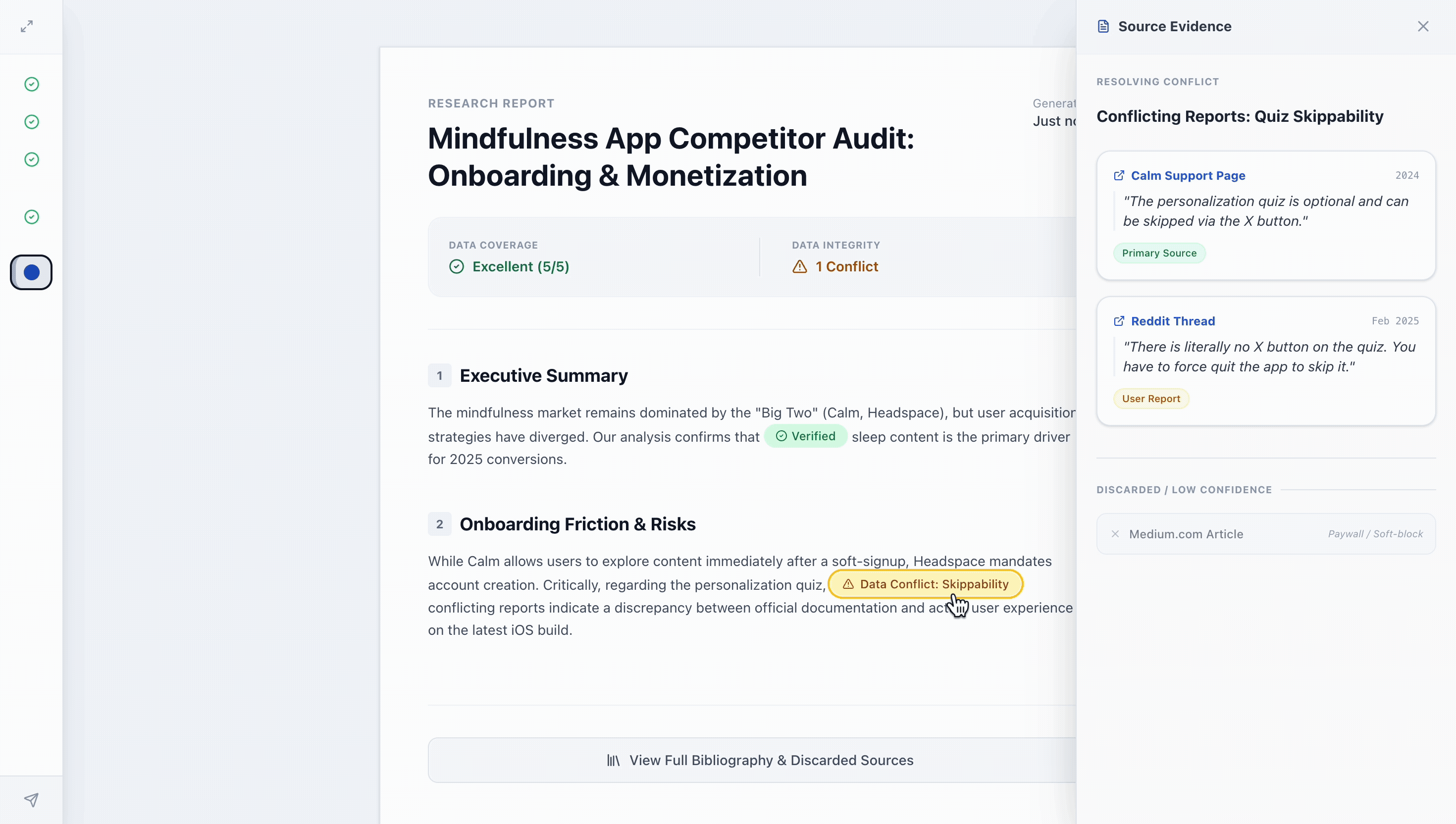
Report Features Health Summary & Interactive Chips
This work explores Human-Agent Collaboration through a human-centered approach that could extend beyond research into other autonomous AI workflow. It imagines the future of agency in deploying autonomous AI agents in professional, high-stakes environments.
Empowering Personalized Agency
The "Glass Box" model shifts the user from a passive consumer of AI output to a Strategic Director. By providing a user-defined alerting logic, the system respects individual "thresholds of trust"—allowing users to decide exactly how much friction and engagement is necessary for their specific task.
Operational Efficiency & Resource Optimization
Beyond trust, the "Decoupled Architecture" delivers tangible technical value. By enabling Micro-Steering, users can catch hallucinations or dead-end paths 30 seconds into a run rather than 10 minutes later. This reduces "runaway" agent tasks, saves expensive compute resources, and significantly reduces the total "human verification tax" required to finalize a report.
Governance Readiness
Approach Cards translate human governance into an interaction pattern: users set expectations for autonomy and evidence standards up front, and the system surfaces traceability and alerts throughout the run. While this doesn’t enforce legal or ethical compliance on its own, it introduces governance primitives (preferences, checkpoints, and audit trails) that help define the agent’s role and can be extended into shared policies, reducing inconsistent “shadow tool” usage.
This project highlights my insightful and valuable exploration into the evolving landscape of human-AI agent interaction. Moving away from simple command-and-response to a nuanced peer-level collaboration through transparency, steerability, and governence, it redefines the human-agent relationship as a form of partnership that human trust and agency is prioritized.
Designing for human augmentation, not just automation.
As agentic systems become increasingly autonomous, we face a critical design paradox: the more capable the agent, the more the user feels a loss of control. From a human-centric approach, I address this by prioritizing Human Augmentation over Automation. Instead of a system that replaces human labor with a black-box output, I believe AI should extend human capabilities through a sustainable, trust-based relationship. In this paradigm, agency and transparency are the critical infrastructure of a successful AI-driven solution.
Unlocking a Landscape of Potential
This 10-week exploration has revealed a vast landscape of potential for enhancing human-agent symbiosis.If I were to iterate further on this work, several critical opportunity areas remain to be further explored:
Mid-Flight Steerability: What does the ideal interaction model look like for fine-tuning agent behavior without disrupting the workflow's momentum?
Dynamic Roadblock Adaptation: How might user-defined rules evolve mid-execution to resolve unexpected obstacles?
Evolving Engagement: How do we support users who wish to transition between high-friction "oversight mode" and low-friction "autopilot" as the task matures?
I'm deeply grateful for the thoughtful critiques and discussions within our research group that shaped this project. It has opened a window into a future where technology doesn't just work for us, but with us.
